OpenAI just released GPT-5.5, and you can now use it as a Codex agent in Superconductor.
We re-ran our "personal SWE-Bench" — based on gold standard PRs into our Ruby on Rails codebase — across every coding agent we support: Codex (GPT-5.5 High/Medium/Xhigh, GPT-5.4 High, GPT-5.3 Codex Spark High), Claude Code (Opus 4.7, Opus 4.6, Sonnet 4.6, Haiku 4.5), Gemini 3.1 Pro, Sourcegraph Amp, and the OpenCode-routed open-weights models (GLM 5.1, Kimi K2.6, Qwen3.6 Plus, MiniMax M2.1).
GPT-5.5 (High) is the new quality-per-dollar leader
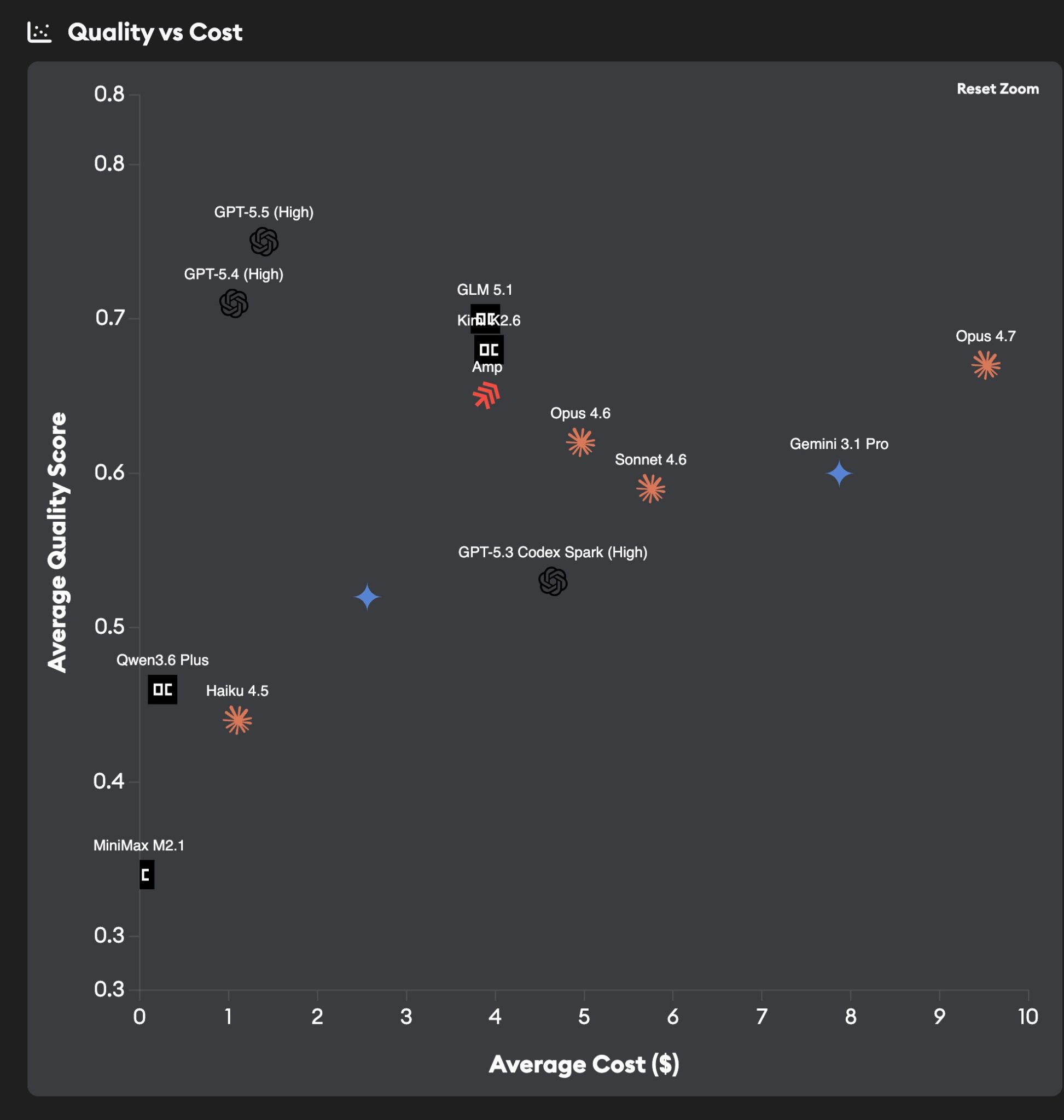
- GPT-5.5 (High) 👑 — Tops the chart at ~0.75 quality for under $1.50/ticket. No other model gets this combination. GPT-5.4 (High) sits just below at ~0.71 quality for ~$1/ticket — still a great budget pick.
- Kimi K2.6 and GLM 5.1 😮 — Both land around 0.69 quality at ~$3.50–$4/ticket, ahead of every Claude model on raw quality. Sourcegraph Amp sits in the same cluster at ~0.66 quality and similar cost.
- Opus 4.7 🤨 — The head-scratcher. Quality is solid (~0.68), but it costs ~$9.50/ticket — roughly 6x what GPT-5.5 (High) costs for a slightly lower score. Hard to justify on economics alone.
- Claude Opus 4.6 and Sonnet 4.6 — Cluster at 0.59–0.62 quality and $5–$5.70/ticket. Solid, but outclassed by the GPT-5 family on this benchmark.
- Gemini 3.1 Pro — ~0.60 quality at ~$8/ticket. Pricey for the quality it delivers here.
- GPT-5.3 Codex Spark (High) — ~0.53 at ~$4.50/ticket. The prior Codex generation has been comprehensively eclipsed.
- Haiku 4.5 — ~0.44 quality at ~$1/ticket. Still useful for low-stakes work.
- Qwen3.6 Plus and MiniMax M2.1 — Bottom-left corner: practically free, but quality drops to 0.46 (Qwen) and 0.36 (MiniMax).
Higher reasoning isn't always better
GPT-5.5 ships with three reasoning levels — High, Medium, and Xhigh — and the ordering surprised us.
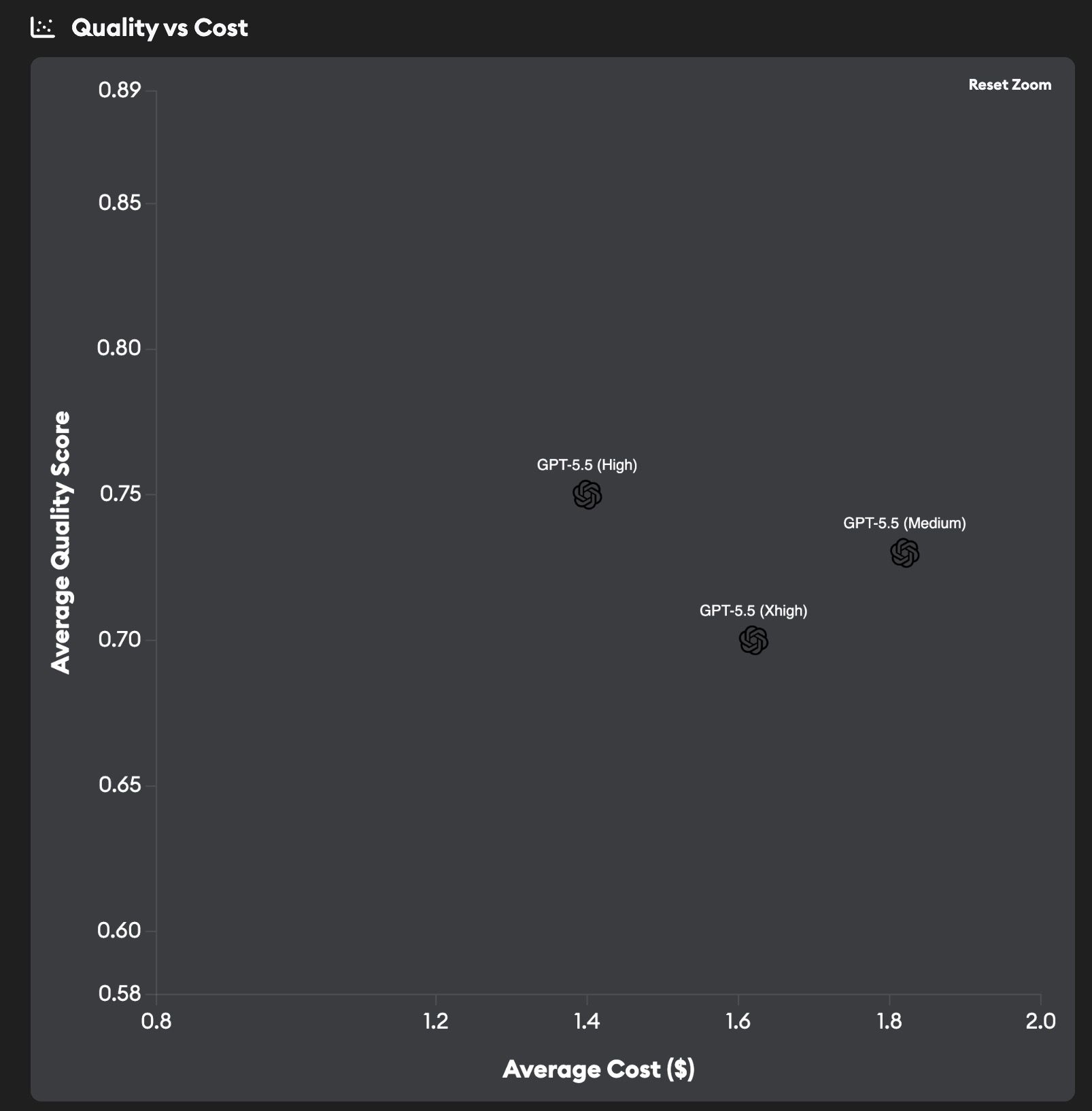
- GPT-5.5 (High): ~0.75 quality, ~$1.40/ticket
- GPT-5.5 (Medium): ~0.73 quality, ~$1.85/ticket
- GPT-5.5 (Xhigh): ~0.70 quality, ~$1.65/ticket
Cranking the reasoning effort up to Xhigh actually hurt quality on our codebase, while costing more than High. Medium lands in between on quality, but at the highest cost of the three. If you're using GPT-5.5 in Codex, High is the level we'd default to.
Quality vs Time: the open-weights tax
Cost isn't the whole story — wall-clock time matters too, especially for human-in-the-loop workflows.
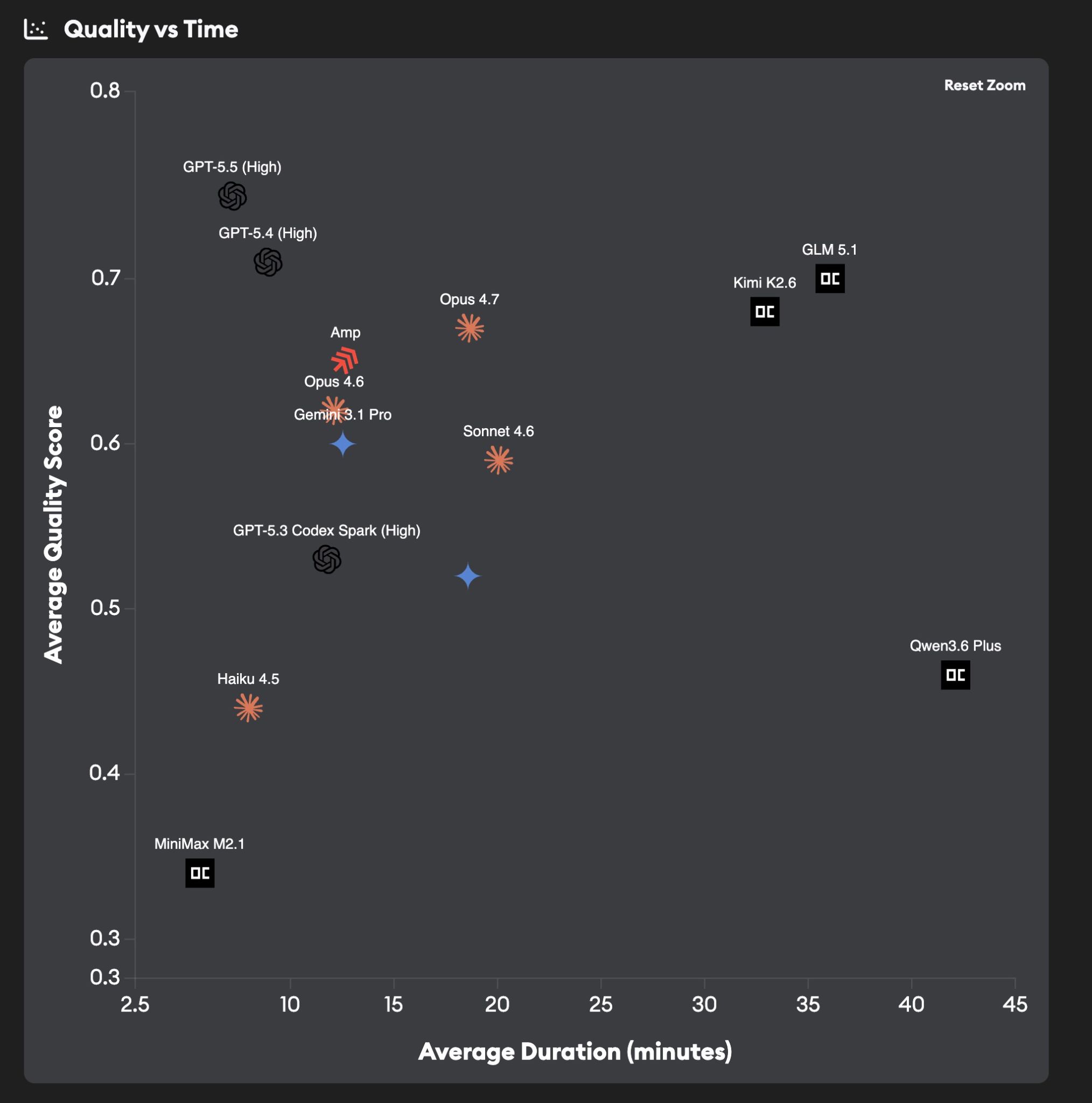
- GPT-5.5 (High) finishes a ticket in ~7 minutes — both the fastest and highest-quality option.
- Haiku 4.5: ~8 minutes. Cheap and quick when quality demands are modest.
- MiniMax M2.1: ~4 minutes — the speed king, but the lowest quality on the chart.
- Opus 4.6, Opus 4.7, Sonnet 4.6, Gemini 3.1 Pro, GPT-5.3 Codex Spark, Amp: 12–20 minute range.
- GLM 5.1, Kimi K2.6, Qwen3.6 Plus: 30–42 minutes per ticket. The open-weights models that match Claude on quality pay for it heavily on speed.
Try GPT-5.5 on your own codebase
Public benchmarks don't tell you how an agent performs on your stack. Our benchmarking feature lets you grade GPT-5.5, Claude Opus 4.7, Sonnet 4.6, Haiku 4.5, Gemini 3.1 Pro, Sourcegraph Amp, GLM 5.1, Kimi K2.6, Qwen3.6 Plus, MiniMax M2.1 — any coding agent you're considering — on real pull requests from your own repos.
Open the Benchmark page in any Superconductor project to run this on your own codebase.