Benchmark
Define your own benchmark using "ground truth" pull requests that your team is proud of, and see how different coding agents perform on it.
Benchmarking helps you find the best coding agent for your specific codebase by comparing quality and cost across agents using real pull requests from your project.
To access benchmarks, open a project and click Benchmark in the project header. From there, you can add Ground Truth PRs, choose agents, configure benchmark-specific startup commands, and start new runs.

Ground truth pull requests
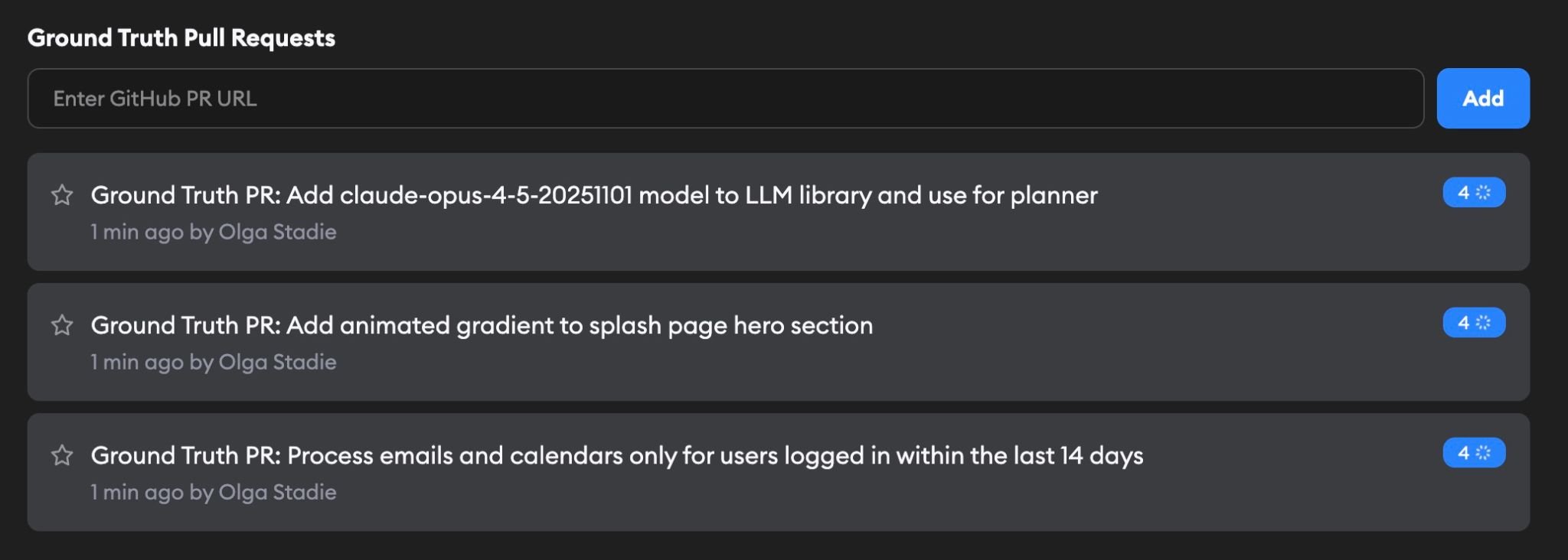
Select some Ground Truth PRs from your project repos that you think are examples of good dev work, then select what agents you'd like to test against them. Include a variety of PR types to teach Superconductor what good code looks like for your project.
For each PR, an AI agent infers the original spec, and tasks each agent with implementing that spec.
A Default run is automatically created when you add your first Ground Truth PR. It serves as a baseline for comparing future runs. New runs you create manually can be compared against the Default run (or any other run) to track how changes to agents or instructions affect performance over time.
Agents

The Agents section shows which coding agents will be tested in your benchmark runs. Configure these by clicking Edit on the benchmark page.
Only agents with configured API keys are available for selection. If an agent is grayed out, add its API key in Project Settings → Agent Credentials first.
The Edit page also includes an optional Benchmark Startup Commands field. These commands run each time a benchmark implementation environment starts, overriding the startup commands from your Development Environment settings. This is useful if your benchmark runs require a different setup than your regular development workflow.
To benchmark Gemini models, configure OpenCode and select an OpenCode profile that uses Gemini. Gemini API keys in Project or Workspace settings are only used for Gemini-powered Superconductor skills, not benchmark agent runs.
Running a benchmark
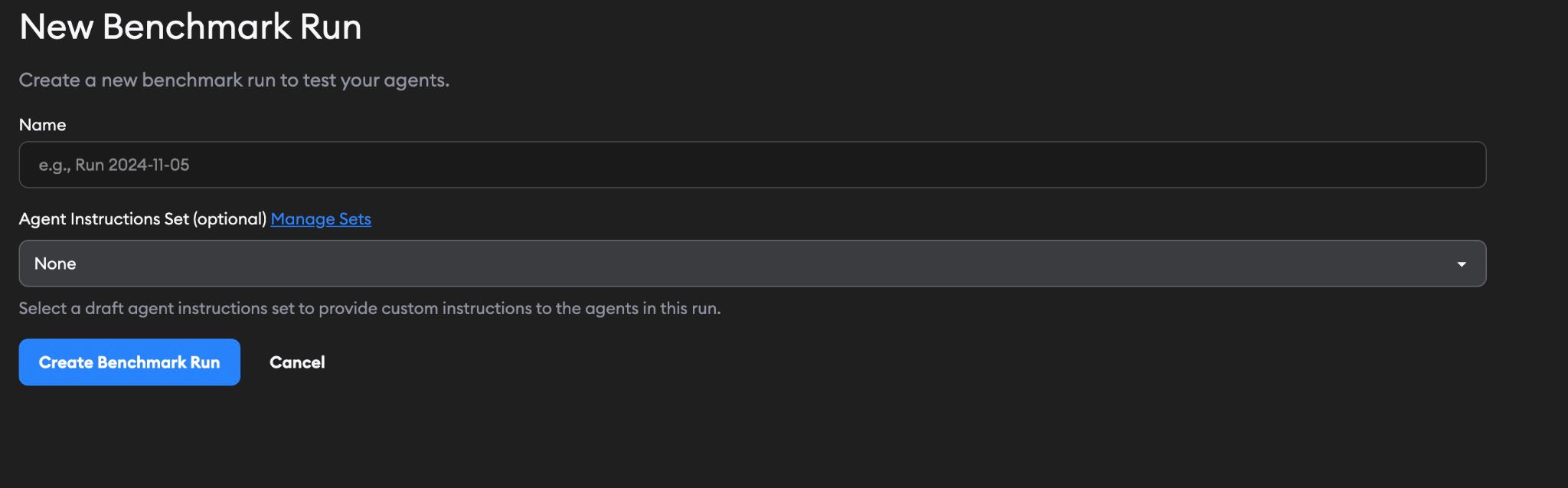
Click New Run to start a benchmark. Give your run a name, and optionally select an Agent Instructions Set.
An Agent Instructions Set lets you provide custom instructions (like the contents of an AGENTS.md or CLAUDE.md file) to the agents during the benchmark run. You can manage these sets from the link on the form. This is useful for testing how agents perform with different instructions.
When you create a run, Superconductor launches implementations for each Ground Truth PR ticket using each selected agent, then evaluates the results.
Benchmark tickets also support manual launches. Open any benchmark ticket and use Launch implementations if you want to rerun a single case with different agents or inspect another implementation outside a full benchmark run.
Evaluation
Each agent's implementation on each Ground Truth PR is then evaluated by multiple LLM judges on a rubric covering correctness, completeness, and code quality. Runtime and cost are tracked as well.
Superconductor runs the evaluations using its own API keys — you don't need to provide keys for the evaluation models.
Results
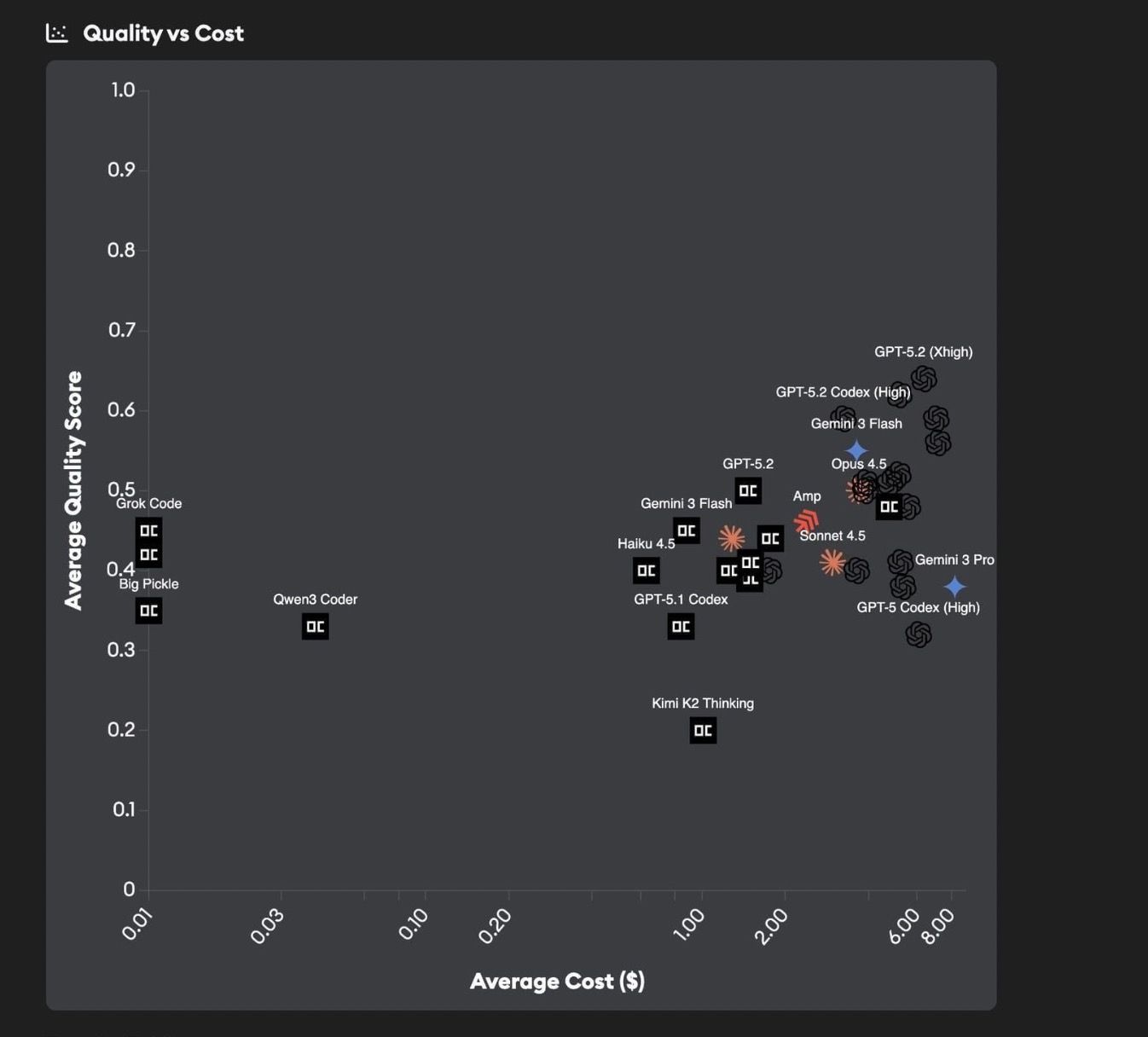
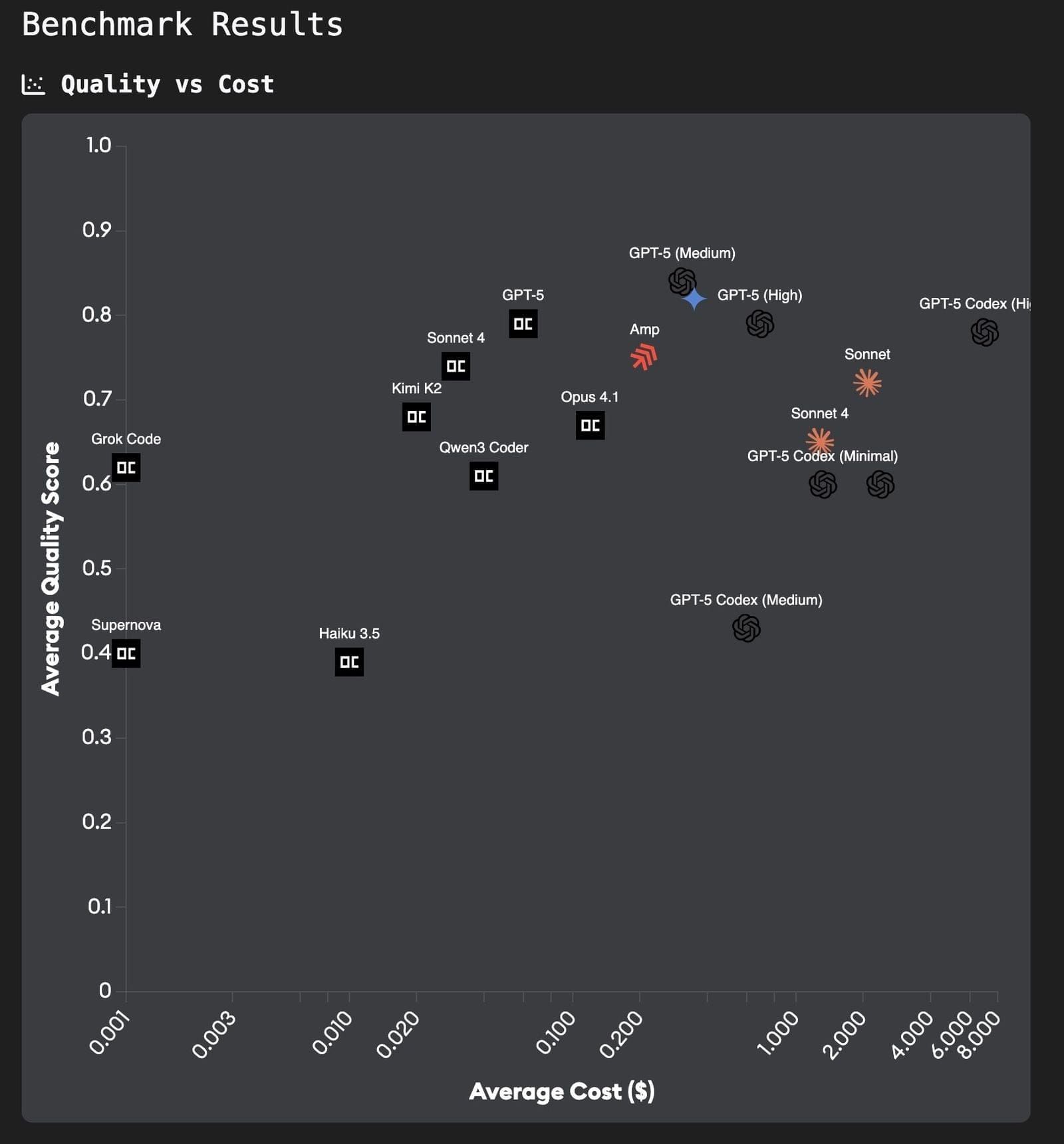
The results are presented on a Quality vs Cost chart and a Quality vs Time chart, letting you compare agents across both dimensions. The quality score is a normalized 0-1 value derived from three 1-5 ratings: correctness, completeness, and code quality, averaged across all three evaluation models.
Hover over any point on the charts to see detailed metrics for that agent. You can drag to zoom into a region of the chart, use Ctrl+click to pan, and click Reset Zoom to return to the default view.
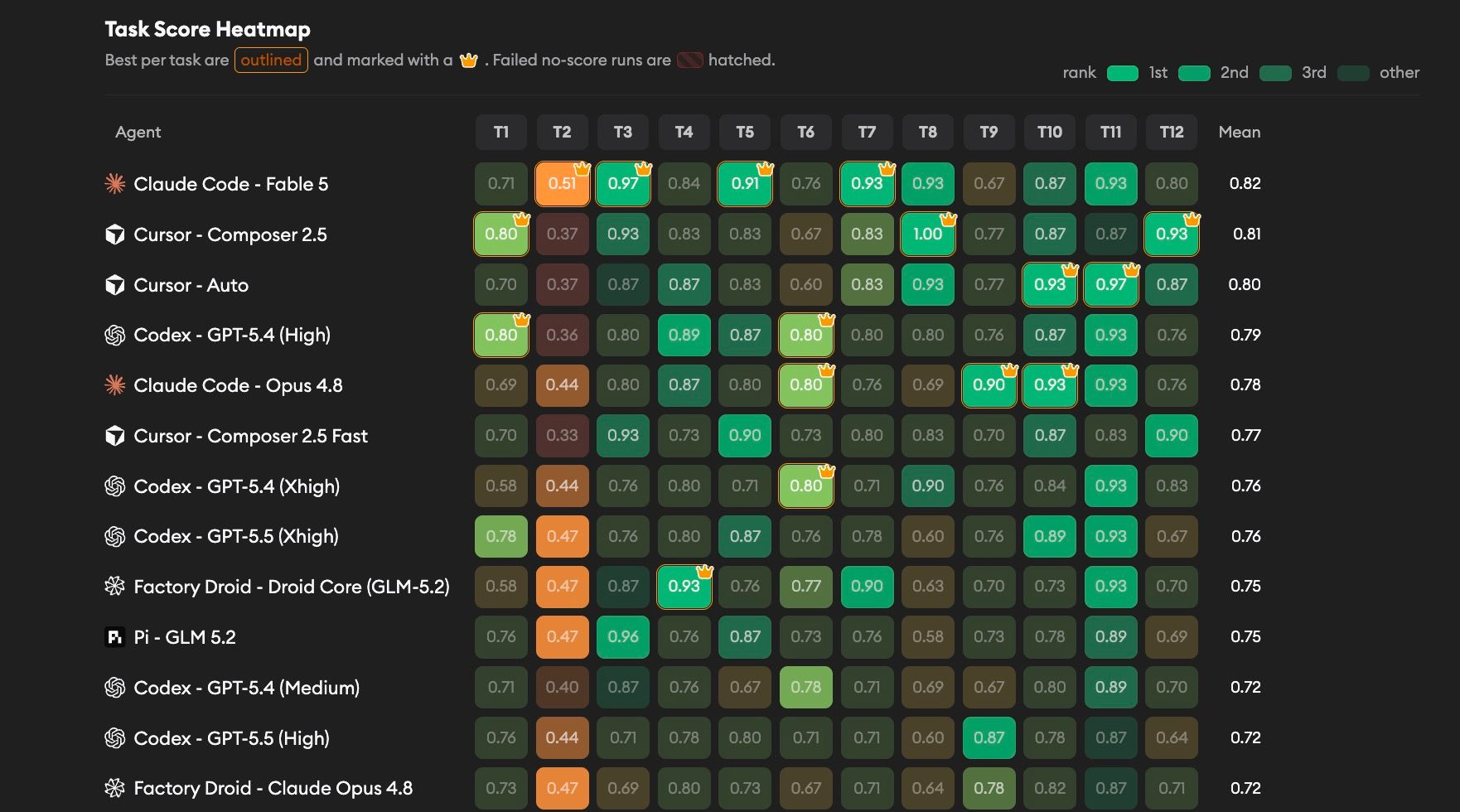
The Task Score Heatmap shows every agent's score on every benchmark ticket. Each row is an agent, each column is a ticket, and the mean column summarizes the agent's overall score. Cells are color-coded by score and shaded by rank, with outlined crown markers for each ticket's winners and hatching for failed runs without scores.
Use the Select Agents button to filter which agents are shown on the charts and tables.
Below the charts, you'll find an Aggregate Results table summarizing each agent's average quality, time, and cost, followed by Results by Ticket tables that break down performance per Ground Truth PR. Each ticket table includes links to the individual implementations where you can review the agent's code and detailed evaluation feedback.
This allows you to see which agents are best matched to your repo, and whether there is a way to have great quality at a lower cost.
Comparison details
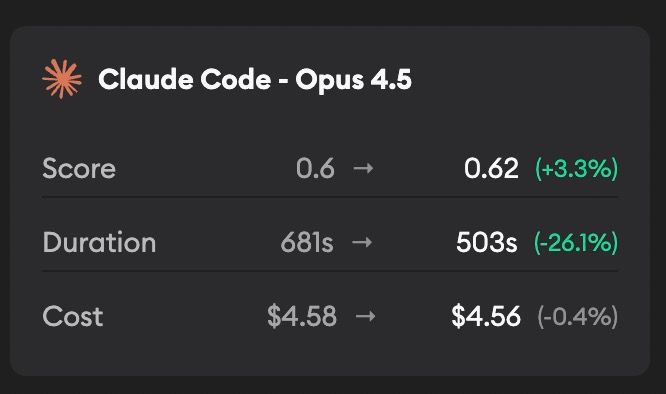
When viewing a non-default run, a Comparison Details section shows how results changed relative to the baseline run, with a dropdown to select which run to compare against. The Quality vs Cost chart will also show two icons per agent with an arrow indicating the direction of change from the baseline to the current run.
Feedback
We'd love to hear how benchmarking is working for you — reach out to us with feedback, questions, or feature requests.