
xAI just released Grok Build, so we benchmarked the new harness and model on our Personal SWE-Bench for Superconductor's Ruby on Rails codebase. The result was better than expected: fast, pretty good, and good enough to join the mix.
The short version: Grok Build is not beating GPT-5.5 or Opus 4.7 on quality, but it is fast and good enough that we are now including it when we launch multiple implementations for tricky tickets.
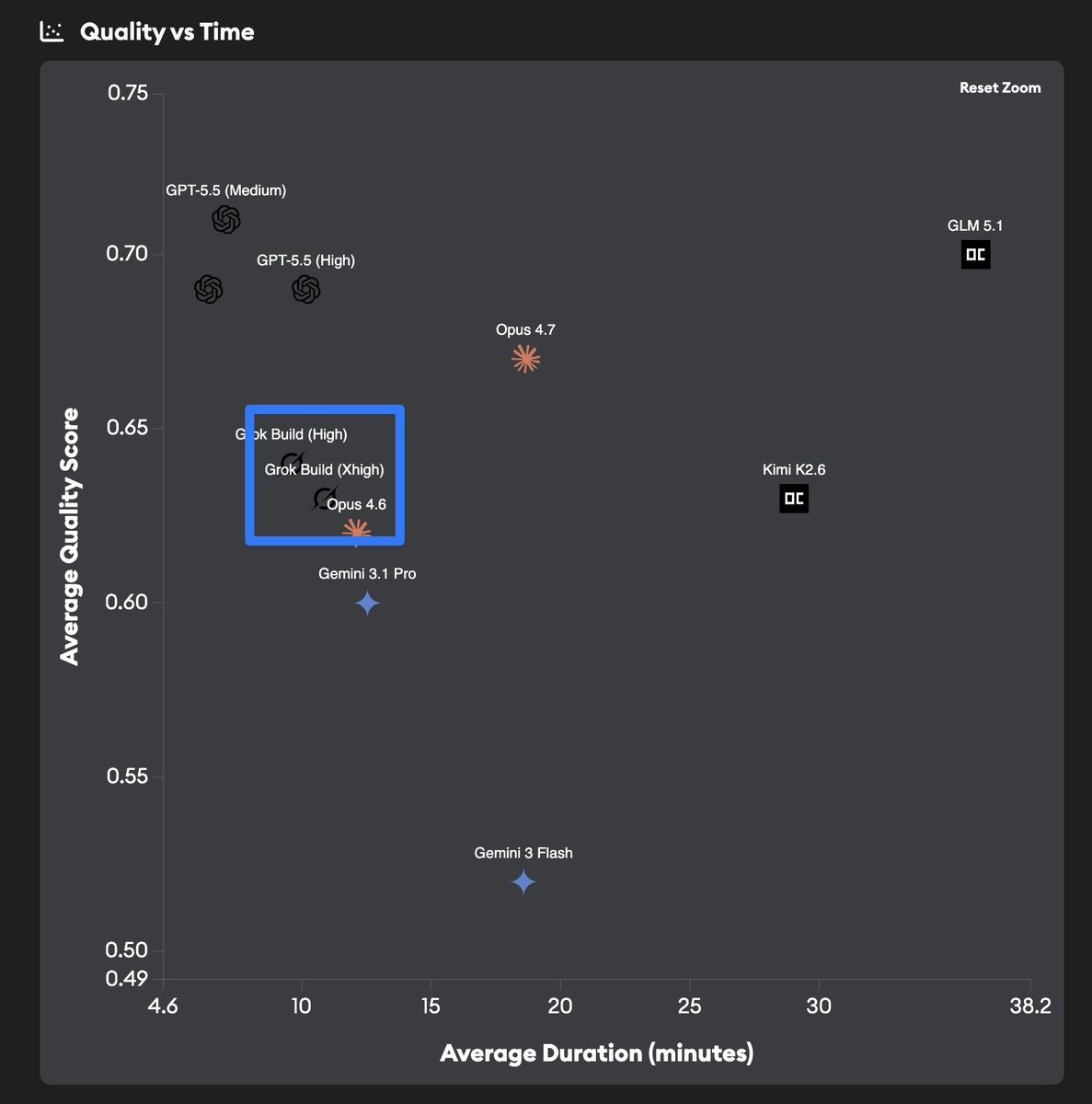
Fast and pretty good
Based on the quality-vs-time chart, Grok Build lands in the middle of the frontier-agent cluster: below GPT-5.5 and Opus 4.7, slightly above Opus 4.6 / Gemini 3.1 Pro territory based on quality on our benchmark, and much faster than the slower open-weights models like Kimi K2.6 and GLM 5.1.
That makes it interesting in practice. For many real tickets, the best agent is not always the one with the highest average score. Sometimes you want a fast second or third opinion, a different architecture take, or another implementation to compare before deciding what to ship.
We saw that in an actual Superconductor ticket too, where we asked GPT-5.5, Opus 4.7, and Grok Build to debug why the ticket form was slow when there are a lot of tickets:
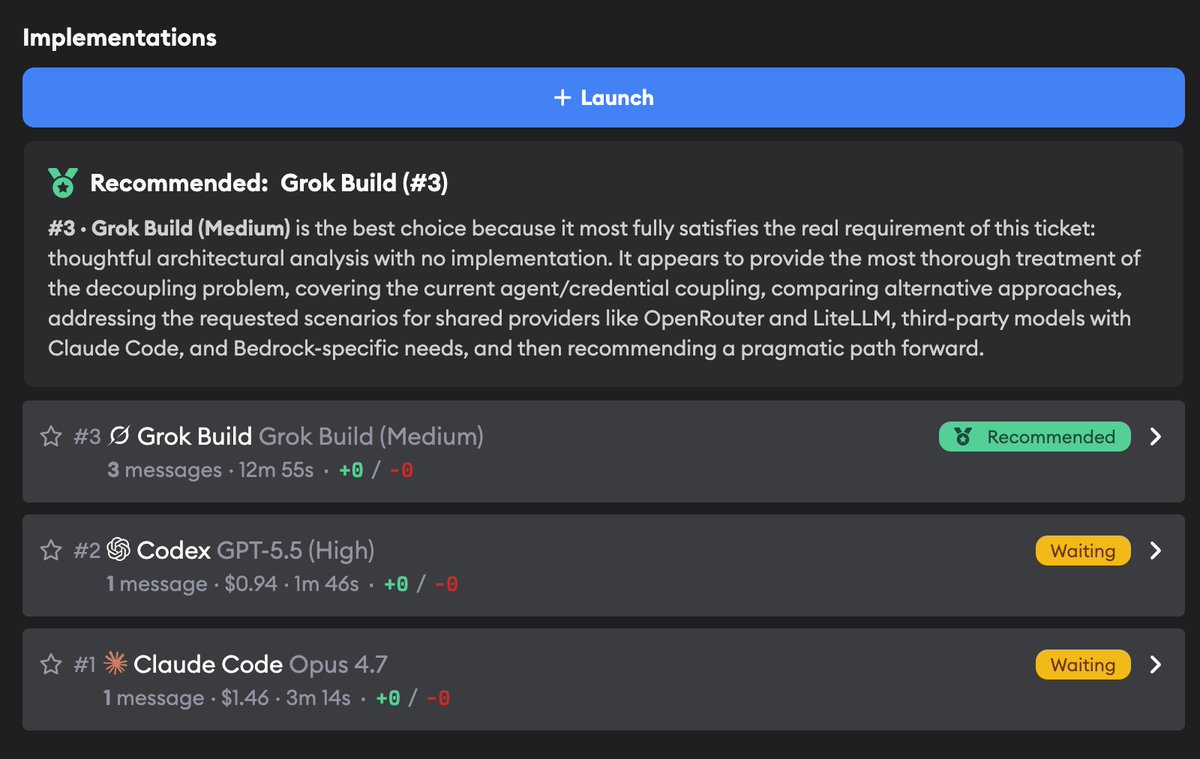
In this case, Grok Build (Medium) produced the most useful architectural analysis for the ticket, and our Implementation Recommendations flow recommended it over GPT-5.5 High and Opus 4.7. That's one ticket, not a universal claim, but it matches the benchmark result: Grok Build is now credible enough to keep in the comparison set.
How our Personal SWE-Bench works
Public benchmarks are useful, but they don't tell you which coding agent works best on your codebase, conventions, framework choices, and review standards.
Superconductor's Benchmarking feature lets you build a Personal SWE-Bench from your own merged pull requests:
- Pick representative merged PRs that reflect good engineering work in your repo.
- Superconductor infers the original ticket spec from each PR.
- Each selected agent implements the spec without seeing the ground-truth solution.
- Separate evaluator models grade correctness, completeness, and code quality.
- Superconductor tracks quality, runtime, and cost so you can compare agents on the tradeoffs that matter.
For this run, Grok Build joined the same comparison pool as Codex, Claude Code, Gemini, and other supported agents.
Try it on your own codebase
Open the Benchmark page in any Superconductor project to run a Personal SWE-Bench on your own repo.
Let us know what models or coding agents you want us to benchmark next!